分布式文件系统--HDFS
概述
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
安装配置
准备服务器
| 服务器名称 | 服务器IP |
|---|---|
| node1 | 192.168.56.101 |
| node2 | 192.168.56.102 |
| node3 | 192.168.56.103 |
接下来的操作需要在上面三台服务器上全部依次操作一遍
下载Hadoop并配置HDFS
我们直接从官网下载hadoop-3.2.0上传到服务器上。
执行以下命令解压文件
$ tar -zxvf hadoop-3.2.0.tar.gz
到解压目录中修改如下配置文件参数:
$ cd hadoop-3.2.0
$ vi etc/hadoop/hadoop-env.sh
#将以下配置放开,并配置成实际的jdk目录
export JAVA_HOME=/usr/local/jdk
$ vi etc/hadoop/core-site.xml
#增加如下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node2:9000/</value>
</property>
</configuration>
$ vi etc/hadoop/hdfs-site.xml
#增加如下配置
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/data/hdfs/name</value>
</property>
##指定datanode软件存放文件块的本地目录
<property>
<name>dfs.datanode.data.dir</name>
<value>/mnt/data/hdfs/data</value>
</property>
##指定sencondary namenode
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
</configuration>
初始化目录并启动
执行以下命令格式化目录
$ cd hadoop-3.2.0/bin
$ ./hdfs namenode -format
执行以下命令启动NodeName
$ ./hdfs --daemon start namenode
执行以下命令启动DataName
$ ./hdfs --daemon start datanode
访问HDFS DASHBOARD页面
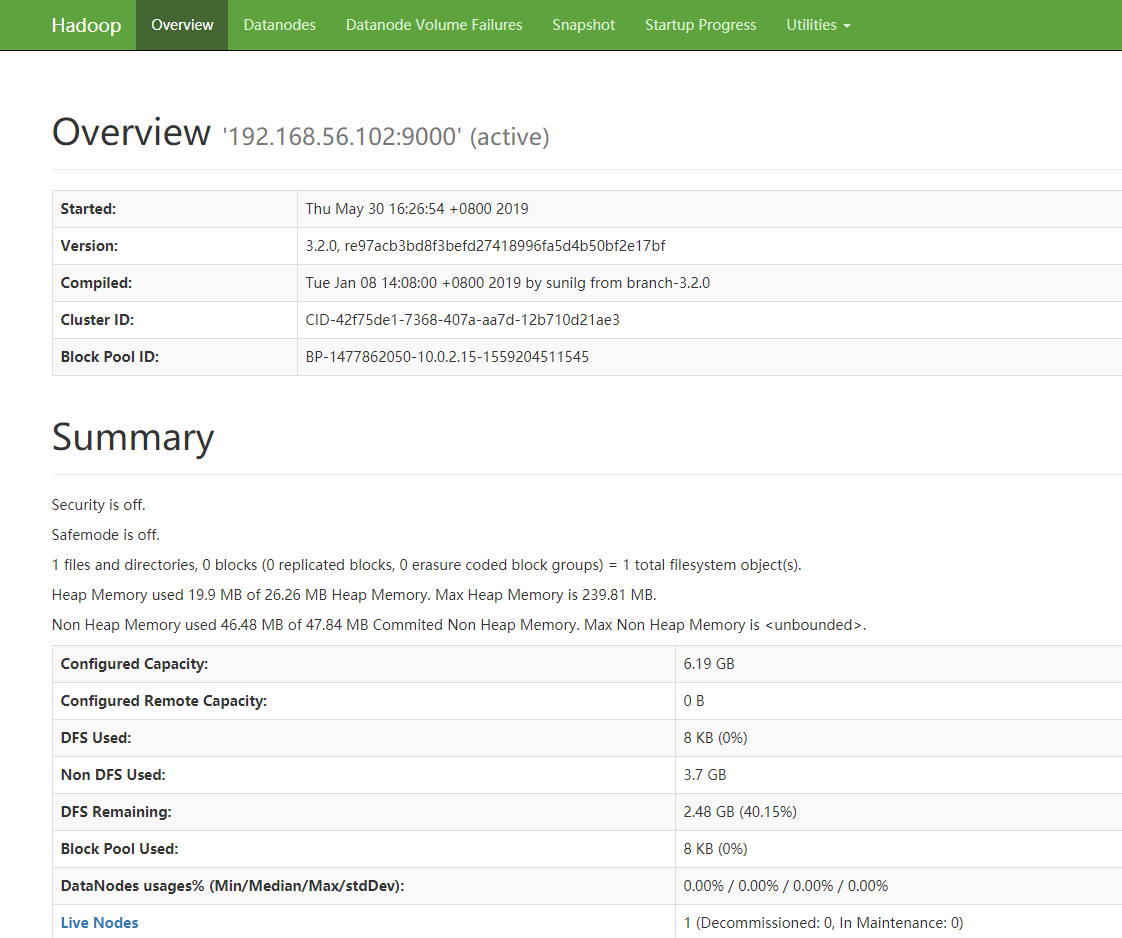
启动成功后,浏览器访问:http://192.168.56.102:9870
看到如下内容表示大功告成
测试文件上传,查看,下载
#在HDFS上创建目录
$ hdfs dfs -mkdir /demo
#上传本地文件到HDFS上
$ hdfs dfs -put t.txt /demo
#查看HDFS上的文件
$ hdfs dfs -cat /demo/t.txt
#从HDFS上下载文件到本地
$ hdfs dfs -get /demo/t.txt
到这里,大家发现hdfs文件系统的操作命令跟操作ftp一样简单。