ElasticSearch分布式搜索引擎搭建
- a、ElasticSearch分布式搜索引擎搭建
- 1、官网下载es安装包:elasticsearch-6.6.2.tar.gz
- 2、上传到Linux服务器上并解压:tar -xzf elasticsearch-6.6.2.tar.gz
- 3、进入到解压目录发现目录结构遵循apache老传统。
- 4、进入到bin目录使用指令./elasticsearch直接运行起来。到这里一般会报错:can not run elasticsearch as root。
- 5、切换到新账号上,再执行4步中的命令启动服务。到这里一般又会报错:max virtual memory areas vm.max_map_count [65530] is too low
- 6、不出意外启动成功后,浏览器访问主机localhost:9200可以看到如下内容,即代表安装成功。
- 7、到这里我们发现搜索引擎服务启动是启动了,但是他并不是分布式集群环境,只是个单结点的玩单机。那么接下来看如下配置集群环境。
- 附:elasticsearch-head可视化插件安装
- b、LogStash分布式数据收集处理管道搭建。
- 1、 官网下载安装包:logstash-6.6.2.tar.gz
- 2、 解压后进入其bin目录执行./logstash-plugin install logstash-input-jdbc安装jdbc插件
- 3、 下载jdbc mysql驱动包
- 4、 新建两个文件jdbc.conf和jdbc.sql,其中jdbc.conf是同步配置文件,jdbc.sql同步的mysql脚本。首先编辑jdbc.conf,填入内容:
以下内容主要介绍给网站建立全局站内搜索服务的业务场景。
接下主要介绍以下内容:
a、ElasticSearch分布式搜索引擎搭建。
b、LogStash分布式数据收集处理管道搭建。
c、演示将mysql中的数据发布到ElasticSearch建立索引,提示搜索服务。
a、ElasticSearch分布式搜索引擎搭建
1、官网下载es安装包:elasticsearch-6.6.2.tar.gz
2、上传到Linux服务器上并解压:tar -xzf elasticsearch-6.6.2.tar.gz
3、进入到解压目录发现目录结构遵循apache老传统。
4、进入到bin目录使用指令./elasticsearch直接运行起来。到这里一般会报错:can not run elasticsearch as root。
错误信息很明显,不要用root账号去启动,该限制是官方强制执行。我们只需要给Linux再创建一个账号即可如:
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
chown -R elsearch:elsearch elasticsearch
特别注意:修改elsearch需要使用到的所有目录的拥有者,确保新建的账号对目录有权限。
5、切换到新账号上,再执行4步中的命令启动服务。到这里一般又会报错:max virtual memory areas vm.max_map_count [65530] is too low
解决该错误,只需要切回root账号并将上述参数改大点如执行命令:sysctl -w vm.max_map_count=655360
6、不出意外启动成功后,浏览器访问主机localhost:9200可以看到如下内容,即代表安装成功。

7、到这里我们发现搜索引擎服务启动是启动了,但是他并不是分布式集群环境,只是个单结点的玩单机。那么接下来看如下配置集群环境。
比如有如下三台服务器
主机1,192.168.56.101
主机2,192.168.56.102
主机3,192.168.56.103
我们只需要按单机版的部署方式,先在三台服务器上都部署一波,步骤完全一致。
那么,如何让这三台服务器建立集群,互相协同工作呢。
只需要在主目录下的config目录找到配置文件:elasticsearch.yml
修改如下节点配置:
#集群名称(三台服务器上配置一样)
cluster.name: cbitedu-cluster
#节点名称(三台服务器上配置不同,例如以各自IP为后缀)
node.name: node_101
#索引等数据存放目录(三台服务器上配置一样)
path.data: /path/to/data
#日志存放目录(三台服务器上配置一样)
path.logs: /path/to/logs
#锁定物理内存地址,防止elasticsearch内存被交换出去,也就是避免es使用swap交换分区(三台服务器上配置一样)
bootstrap.memory_lock: true
#服务绑定IP(三台服务器上配置不同,分别配置各自IP地址)
network.host: 192.168.56.101
#服务绑定端口(三台服务器上配置一样)
http.port: 9200
#集群服务器各节点的IP地址,端口默认是9300可不配置(三台服务器上配置一样)
discovery.zen.ping.unicast.hosts: [“192.168.56.101”, “192.168.56.102”, “192.168.56.103”]
#通过配置这个参数来防止集群脑裂现象 (集群总节点数量/2)+1(三台服务器上配置一样)
discovery.zen.minimum_master_nodes: 2
#一个集群中的N个节点启动后,才允许进行数据恢复处理,默认是1(三台服务器上配置一样)
gateway.recover_after_nodes: 3
配置完成后群集环境就弄好,三台服务器上的服务全部启动起来,就会建立搜索引擎集群环境。
附:elasticsearch-head可视化插件安装
#下载head插件源码
git clone https://github.com/mobz/elasticsearch-head.git
#下载node环境
wget https://npm.taobao.org/mirrors/node/latest-v11.x/node-v11.12.0-linux-x64.tar.gz
vi /etc/profile
将下载并解压出来的node主目录下的bin目录配置到环境变量中去,并执行source /etc/profile使之生效
#安装head
npm install phantomjs-prebuilt@2.1.16 –ignore-scripts
#启动head插件
npm run start
访问9100端口即可看到可视化界面
界面是出来了,但不要高兴得太早,我们会发现这个界面并不能连接上我们所搭建的ES集群服务,这是因为我们还缺少一个步骤,解决跨域问题。
只需要在ES配置文件中加上以下两行代码即可解决:
http.cors.enabled: true
http.cors.allow-origin: “*”
至此大功告成
b、LogStash分布式数据收集处理管道搭建。
1、 官网下载安装包:logstash-6.6.2.tar.gz
2、 解压后进入其bin目录执行./logstash-plugin install logstash-input-jdbc安装jdbc插件
3、 下载jdbc mysql驱动包
4、 新建两个文件jdbc.conf和jdbc.sql,其中jdbc.conf是同步配置文件,jdbc.sql同步的mysql脚本。首先编辑jdbc.conf,填入内容:
input {
stdin {
}
jdbc {
# mysql jdbc connection string to our backup databse 后面的ktsee对应mysql中的test数据库
jdbc_connection_string => "jdbc:mysql://localhost:3306/cbitedu"
# the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => "password"
# the path to our downloaded jdbc driver 这里需要设置正确的mysql-connector-java-5.1.46.jar路径,找不到可以从网上下载后放在配置路径中
jdbc_driver_library => "/elasticsearch-6.6.2/lib/mysql-connector-java-5.1.46.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
# 以下对应着要执行的sql的绝对路径
statement_filepath => "/creatorblue/data/es/jdbc.sql"
# 定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 设定ES索引类型
type => "cbitedu_index"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
#ESIP地址与端口(上面搭建的ES集群)
hosts => ["192.168.56.101:9200","192.168.56.102:9200","192.168.56.103:9200"]
#ES索引名称(自己定义的)
index => "cbitedu_index"
#自增ID编号
document_id => "%{id}"
}
stdout {
#以JSON格式输出
codec => json_lines
}
}
接下来就是编写jdbc.sql文件了,里面的脚本就是你想要提供给搜索引擎检索的数据,例如 select * from t_news_info 将所有新闻数据发布出去让elasticsearch提供检索服务
最后就是启动logstash服务了,cd到主目录,执行以下命令:
nohup bin/logstash -f cbitedu/cbitedu.conf > logs/logstash.out &
到这里Logstash就成功启动了,但是依然是单节点单机,要部署多结点,只需要复制一份,确保data目录不一致即可。
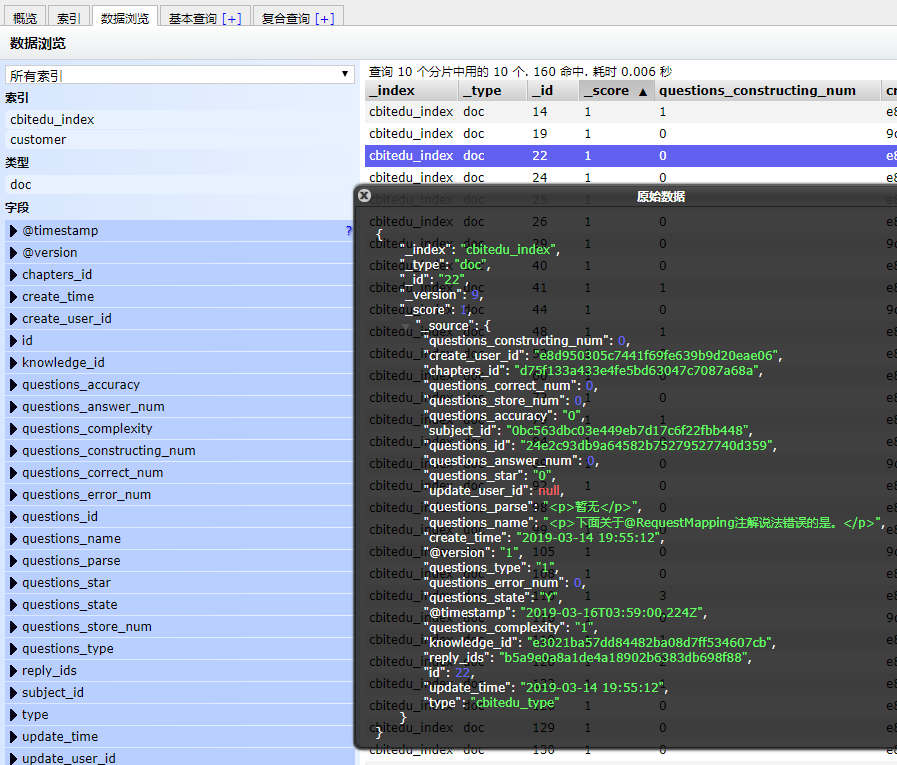
这个时候可以回过去看ES head插件可视化安装章节中的示例图,图中的数据就是上面sql查询出来的数据了
#查看ES集群中所有索引
http://127.0.0.1:9200/_cat/indices?v
#查看cbitedu_index索引中的内容
http://127.0.0.1:9200/cbitedu_index/_search?pretty